PDFファイルから指定の項目値をテキスト抽出するツールの紹介

皆さん、こんにちは。
私は普段、法人向けにクラウドサービスの導入支援や社内システムの改善担当をしております。
今回、弊社のお客様よりPDFファイル形式の大量の契約書から正確に特定の項目値を抽出し、CSVファイルにて出力してほしいという依頼を頂きました。
PDFファイルから文字データを抽出するツールや、OCRやAI-OCRといったサービスがありますが、文字の認識や抽出の精度が低いものもあり、データ抽出後の内容確認作業に意外と時間を取られることがないでしょうか。
そこで、弊社が開発した「PDFテキスト抽出ツール」が、お客様より高評価を頂いたので、本記事にて紹介させていただきます!
【目次】
【お客様からの要望】
お客様から頂いた要望は主に、以下の内容となります。
- お客様がこれまで締結してきた様々な契約書関連のPDFファイル約5000件から特定の契約書のみを対象として指定項目値を抜き出し、CSVファイルを作成する。
- 抽出対象とならなかった契約書は対象外一覧表として別のCSVファイルを作成する。
- 正確に指定の項目値を抽出する。
(OCR、AI-OCRで発生する誤読はないようにしてほしい)
下記に「PDFテキスト抽出ツール」の特徴と使用方法について紹介したいと思います!
【PDFテキスト抽出ツールの特徴】
- 指定のフォルダ内にある複数のPDFファイル内の全文をテキスト抽出できます!
- 抽出されたテキスト内から指定のキーワードを手掛かりに文字列を抽出、更にトリミングなどの加工も加えてCSVファイルへ記述することが可能です!
- 抽出する文字列の位置や文字数など細かく指定し抽出を行うため、完全な定型フォーマットで生成されたPDFファイルであればOCRやAI-OCRの様な誤読は無く100%の認識精度で項目値を読み取る事が可能です!
注意:スキャナにて取り込まれたPDFファイルは本ツールの対象外となります。
対象となるものは特定のシステムにより自動生成されたPDFファイルとなります。
(SaaS契約時に自動生成された契約書など)
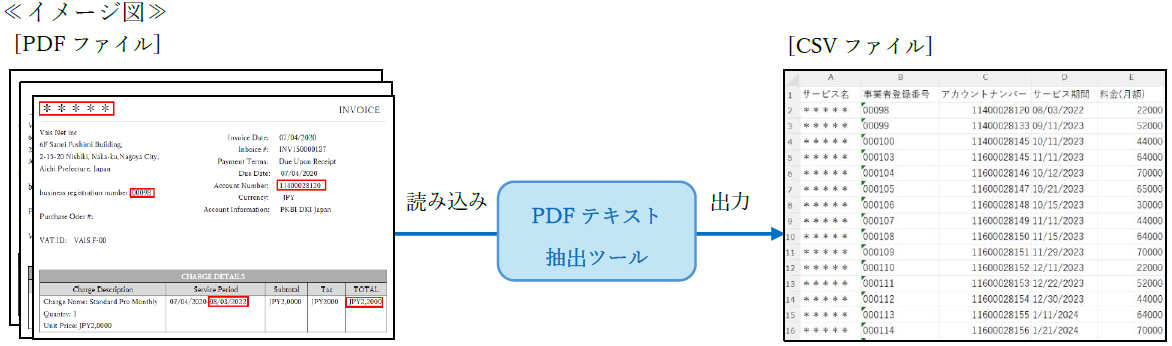
文字列の抽出は、「全文読み込み」「切り出し」「区切り」「加工」「期待値判定」の5つの工程で行われます。
| 工程 | 内容 |
| 全文読み込み | 対象のPDFファイルの全文を読み込みます |
| 切り出し | 読み込んだテキスト情報から指定文字列を抽出します ※抽出する文字の位置や抽出する文字数といった細かい指定が可能です |
| 区切り | 切り出した文字列に対し、指定した区切り文字n番目の文字列抽出が可能です |
| 加工 | 切り出した文字列に対し、置き換えや一部文字の削除等の編集が可能です |
| 期待値判定 | 判定条件を設定し、切り出した文字列が該当しているか判定を行います その後、加工等の編集工程に分岐させることが可能です |
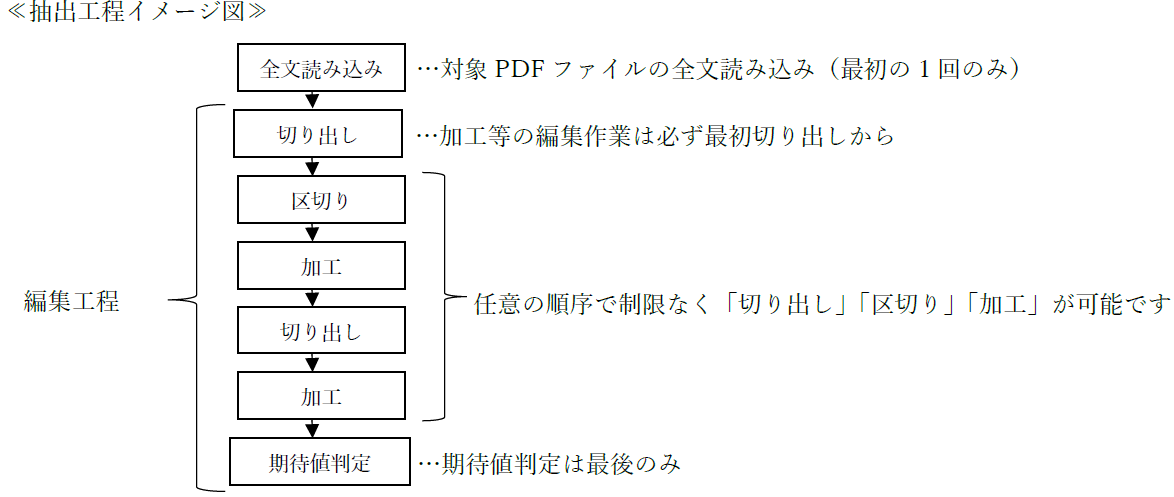
※「編集工程」は必須ではありません。「編集工程」を行わない、または「切り出し」の
み行うといったことも可能です。
下記に各工程の活用例を紹介します。各工程を組み合わせることで幅広いテキスト抽出が可能です!
《切り出し》
| 活用例 | 設定 | 切り出し箇所 | 結果 |
| 指定した検索キーワード にて最初にヒットしたワ ードの隣から行末まで切 り出し | キーワードを[Account Number: ]とする | Due Date: 07/04/2020 Account Number: 11400028120 Currency: JPY | 11400028120 |
| 検索キーワードを2つ指 定し1つ目のキーワード にヒットした場所から2 つ目のキーワードがヒッ トした場所まで切り出し | 1つ目のキーワードを[Account Information: ] 2つ目のキーワードを[Japan]とする | Currency: JPY Account Information: PKBI DKI Japan | PKBI DKI |
| 指定した検索キーワード にて最初にヒットしたワ ードからn 行下を行末ま で切り出し | キーワードを[Due Date:]とする キーワードがヒットした行の3行下を抽出 | Due Date: 07/04/2020 Account Number: 11400028120 Currency: JPY | Currency: JPY |
| 指定したキーワード検索 にてn番目にヒットした キーワードを含み行末ま で切り出し | キーワードを[JPY]とする 2番目にヒットしたものを抽出 | 07/04/2020-08/03/2022 JPY2,0000 JPY2000 | JPY2000 |
《区切り》
| 活用例 | 設定 | 区切り箇所 | 結果 |
| ある文字で区切った中のn番目 | [,]を区切り文字とし、2番目を取り出す | Aichi Prefecture, Japan | Japan |
《加工》
| 活用例 | 設定 | 加工箇所 | 結果 |
| 改行を取り除く | apple, orange | apple,orange | |
| 前後の空白を取り除く | □JPY2,0000□ | JPY2,0000 | |
| 数字に不要な文字を取り除く | JPY2,0000 | 2,0000 | |
| n文字目から m 文字を取り出す | 11文字目から4文字以外削除 | VATID:VAIS F-00 | F-00 |
| ある文字を別の文字に置き換える | [orange]を[みかん]へ置き換え | apple,orange,grape | apple, みかん,grape |
| 日付をyyyy/mm/dd 形式に変換する | Jun 30, 2021 | 2021/06/30 | |
| ある文字を付け足す | [@example.com ]を付け足す | apple | apple@example.com |
《期待値判定》
| 活用例 | 設定 | 加工箇所 | 結果 |
| 日付であることを期待 し、そうでなければ別 の文字に置き換える | 「日付でない」に置き換える | 2021/06/30 | 2021/06/30 |
| apple | 日付でない | ||
| 空白以外は何でもOK、 そうでなければ別の 文字に置き換える | 「空白禁止」に置き換える | apple | apple |
| 空白禁止 | |||
| $表記の価格である ことを期待し、そう でなければ別の文字 に置き換える | 「抽出エラー」に置き換える | $100,000 | $100,000 |
| 100,000 | 抽出エラー | ||
| ある単語に合致する ことを期待し、そう でなければ別の文字 に置き換える | 「東京都」を単語とする 「抽出エラー」に置き換える | 東京都 | 東京都 |
| 愛知県 | 抽出エラー |
【PDFテキスト抽出ツールの使用方法】
「PDFテキスト抽出ツール」の使用方法について紹介します。
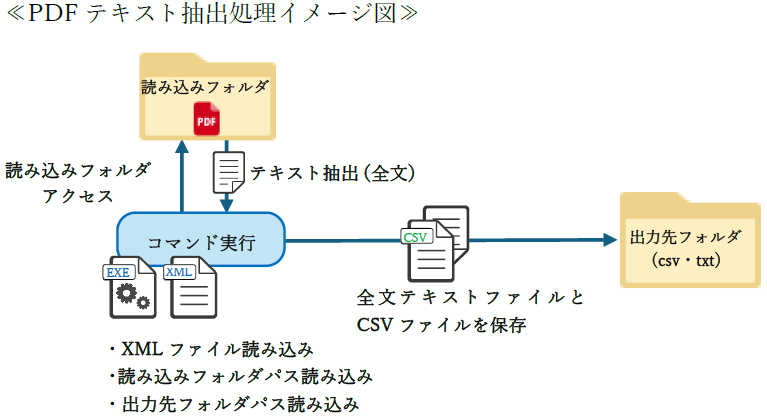
使用方法はコマンドプロンプトやショートカットから実行ファイル(EXE)にパラメータを付与して実行します。
※XMLファイル内に抽出する文字列の「切り出し」や「加工」等の編集工程を記述します。
〈書式〉
[EXEファイルパス]/setting [XMLファイルパス]/input [PDF読み込み先パス]/
output [CSV出力先パス]
上記コマンドを実行することで読み込み先フォルダ内の全てのPDFファイルに対しXMLファイルの内容が適用されます。その後文字列抽出が行われ、指定の出力先フォルダ内へCSV出力されます。
また対象ファイルの全文を記述したテキストファイルも出力することが可能です。
《XMLファイル記述例》
XMLファイルには最初の工程で取得した対象ファイルの全文からどの場所の文字列を抽出、編集しCSVファイルの何列目に記述するかを指定します。
実際に対象ファイルの全文からXMLファイルを適用した際のCSV出力結果を下記に紹介します!
〈対象PDFファイルの全文(複数)〉
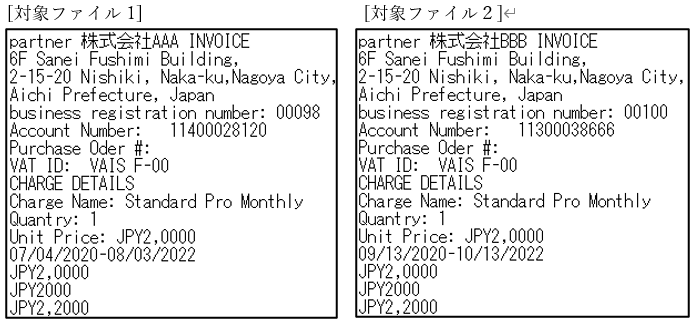
〈記述例〉
記述方法は主に「output」内に出力するCSVファイルのフィールド名を指定し、「field」内に対応したフィールドに入力する文字列の抽出方法を指定します。

| コード | 内容 |
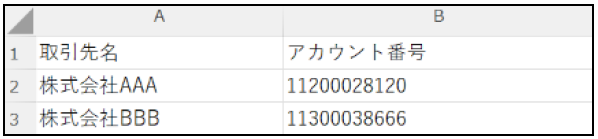
| <output> <item column=’1′ header=”取引先名” number=’1′ /> <item column=’2′ header=”アカウント名” number=’2′ /> </output> | 出力するCSVファイルの1列目のフィー ルド名を「取引先」2列目を「アカウント 番号」とし、以降に記述する抽出指定に 紐づくようfield numbeを設定 |
| <field number=’1′> <extract cmd=’cut’ word=’partner’ cutStart=’beside’ range=’wordBeside’ rangeWord=’INVOICE’ /> <extract cmd=’modify’ trimSpace=’true’ /> </field> | 抽出した文字列を出力するCSVファイル 1列目へ入力する。 キーワード「partner」にヒットした文字 列の隣から最初にヒットする文字列 「INVOICE」の直前までを抽出。 更に抽出した文字列の前後にスペースが あれば削除。 |
| <field number=’2′> <extract cmd=’cut’ word=’Account Number’ cutStart=’beside’ range=’CR’ /> <extract cmd=’modify’ trimSpace=’true’ /> </field> | 抽出した文字列を出力するCSVファイル2列目へ入力する。 キーワード「Account Number」にヒッ トした文字列の隣から行末までを抽出。 更に抽出した文字列の前後にスペースがあれば削除。 |
〈CSV出力結果〉
【kintoneでの一括登録作業にも使える!】
「PDFテキスト抽出ツール」は出力するCSVファイルのフィールド名や抽出した文字列の編集も細かく行えるため、CSVファイルをインポートして一括登録などを行えるサービスとの相性が良いです。
例えば、クラウドサービスのkintoneを使用して、定型フォーマットにて作成された大量のPDF形式の契約書内容を一括登録するといった作業を簡略化することも可能です。
kintoneは指定のフォーマットで作成されたCSVファイルをインポートし一括でデータ登録をレコード単位で行うことが可能です。そこで今回の「PDFテキスト抽出ツール」にて指定の契約書から指定の項目値を抽出後に出力するCSVファイルのフォーマットをkintone指定のフォーマットに合わせてしまえば、kintone側ではPDFテキスト通出ツールにて出力されたCSVファイルをインポートするだけで一括登録することが可能です!
【まとめ・感想】
今回紹介しました「PDFテキスト抽出ツール」は定型フォーマットにて自動生成されたPDFファイルの一括管理や他システムでのCSVインポートといった作業にとても向いています!
またOCR、AI-OCRを使用した際に起こりうる誤読といった部分も回避できるため正確なテキスト抽出を行いたい作業にもとても向いています!
まだまだ機能や使用方法について紹介し足りない部分もありますが、もし「PDFテキスト抽出ツール」に興味を持っていただけましたら気軽に弊社までご連絡、ご相談ください!
最後までお読みいただきありがとうございました!